



¿Qué es el caching?
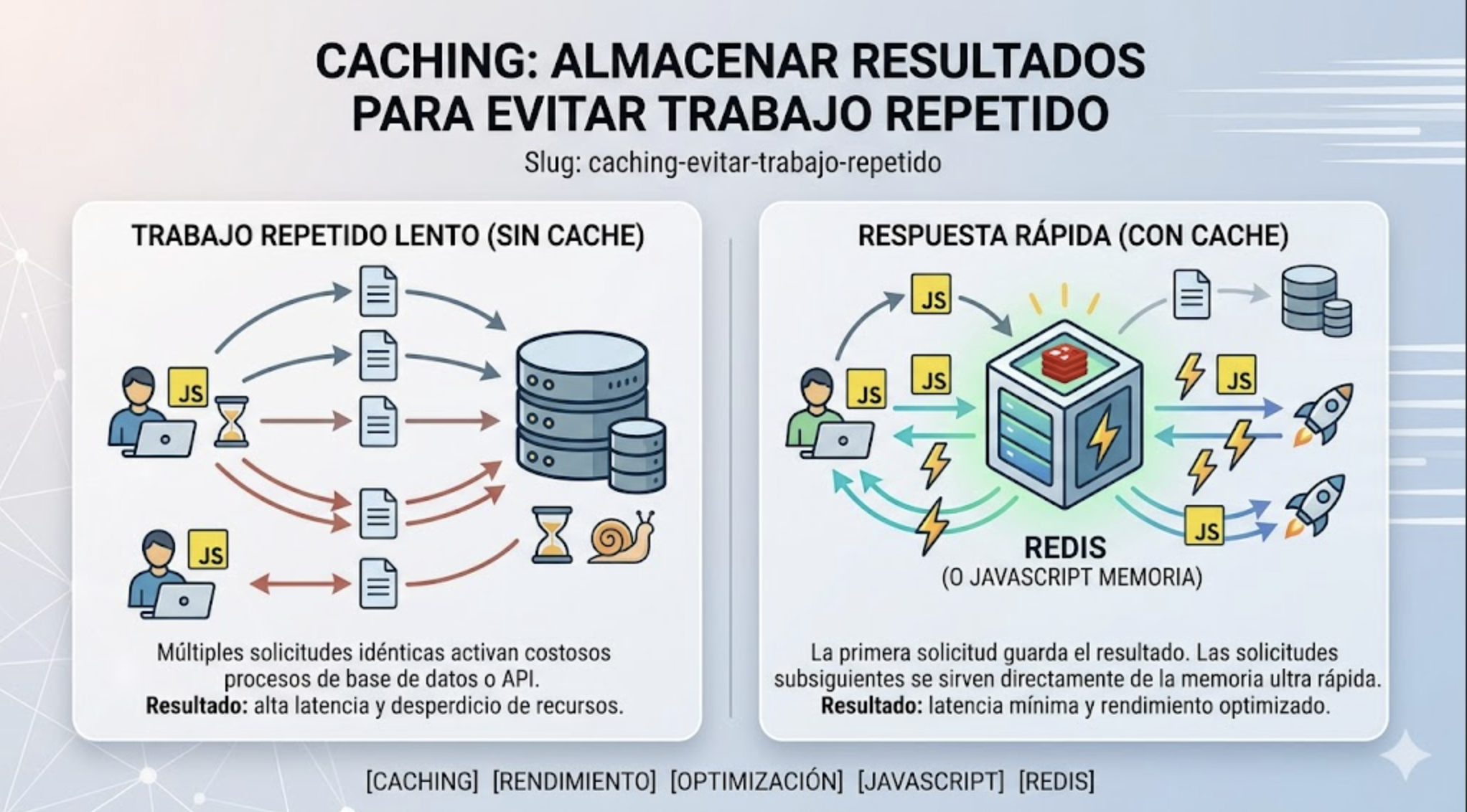
El caching consiste en guardar el resultado de una operación costosa para reutilizarlo más tarde, en lugar de calcularlo otra vez. La idea es simple: si ya hiciste el trabajo una vez y el resultado no cambió, no tiene sentido repetirlo.
Esa "operación costosa" puede ser una consulta a la base de datos, una llamada a una API externa, un cálculo pesado o el renderizado de una página. El caché actúa como un intermediario rápido que responde con el resultado ya listo.
Cómo funciona
Un caché funciona como un diccionario: una clave apunta a un valor. Cuando llega una petición, se busca la clave:
Si el valor está guardado, es un cache hit: se devuelve de inmediato.
Si no está, es un cache miss: se ejecuta el trabajo real, se guarda el resultado y se devuelve.
El objetivo es maximizar los hits, porque ahí está el ahorro: menos latencia, menos carga sobre los sistemas y, en muchos casos, menos costo (sobre todo cuando cada llamada a una API o a una base de datos se paga).
Dónde se aplica
El caching aparece en casi todas las capas de una aplicación: el navegador guarda imágenes y scripts, la CDN sirve contenido estático desde servidores cercanos, la aplicación mantiene resultados en memoria y la base de datos reutiliza consultas recientes.
Caching en la práctica con JavaScript
Memoización: evitar repetir trabajo con los mismos argumentos
Si una función se llama varias veces con los mismos argumentos, podemos guardar el resultado la primera vez y reutilizarlo. La clave del caché se arma a partir de los argumentos:
function memoize(fn) {
const cache = new Map();
return (...args) => {
const key = JSON.stringify(args);
if (cache.has(key)) return cache.get(key); // cache hit
const result = fn(...args);
cache.set(key, result);
return result;
};
}Deduplicar peticiones en vuelo
Un caso muy común: varios componentes piden el mismo dato casi al mismo tiempo y se disparan peticiones idénticas. Guardando la promesa en curso, todas reutilizan la misma respuesta:
const inFlight = new Map();
function fetchUser(id) {
if (inFlight.has(id)) return inFlight.get(id);
const promise = fetch(`/api/users/${id}`)
.then((res) => res.json())
.finally(() => inFlight.delete(id));
inFlight.set(id, promise);
return promise;
}TanStack Query en el frontend
En lugar de manejar todo esto a mano, TanStack Query lo resuelve por nosotros. La queryKey cumple el rol de clave del caché: si dos componentes usan la misma key, comparten el resultado y las peticiones simultáneas se deduplican automáticamente.
import { useQuery } from '@tanstack/react-query';
function useUser(id: string) {
return useQuery({
queryKey: ['user', id],
queryFn: () => fetch(`/api/users/${id}`).then((res) => res.json()),
staleTime: 60_000, // el dato se considera "fresco" 1 minuto
});
}Con staleTime controlamos cuánto tiempo un dato se considera fresco antes de volver a pedirlo, y la librería gestiona la invalidación cuando hace falta.
Redis en el backend
En el servidor, Redis es la opción habitual para cachear consultas a la base de datos. El patrón más usado es cache-aside: buscar primero en el caché y, si no está, ir a la base de datos y guardar el resultado con un tiempo de expiración (TTL).
async function getProduct(id: string) {
const cacheKey = `product:${id}`;
const cached = await redis.get(cacheKey);
if (cached) return JSON.parse(cached); // cache hit
const product = await db.product.findUnique({ where: { id } });
await redis.set(cacheKey, JSON.stringify(product), 'EX', 300); // TTL 5 min
return product;
}Cuando el dato cambia, hay que invalidar la entrada para no servir información vieja:
async function updateProduct(id: string, data: ProductData) {
const product = await db.product.update({ where: { id }, data });
await redis.del(`product:${id}`); // invalidar el caché
return product;
}El problema difícil: la invalidación
Hay una frase conocida en programación: lo difícil del caching no es guardar datos, sino saber cuándo dejaron de ser válidos. Si los datos cambian pero el caché sigue devolviendo la versión vieja, el usuario ve información incorrecta (stale data).
Las estrategias más comunes son el TTL (el dato expira tras un tiempo definido), la invalidación por evento (se borra la entrada cuando el dato original cambia) y las políticas de desalojo como LRU, que descartan lo menos usado cuando el caché se llena.
Riesgos a tener en cuenta
Datos desactualizados: el equilibrio entre frescura y rendimiento depende del caso.
Cache stampede: si muchas peticiones llegan justo cuando una entrada expira, todas intentan recalcular a la vez y saturan el sistema.
Memoria limitada: un caché mal dimensionado consume recursos sin aportar valor real.
Buenas prácticas
Cachea lo que es costoso de calcular y se lee con frecuencia, no todo por defecto.
Define una estrategia de invalidación antes de implementar el caché.
Mide la tasa de aciertos (hit rate): si es baja, el caché no está ayudando.
Empieza simple y ajusta según datos reales, no suposiciones.
El caching es una de las herramientas más efectivas para mejorar rendimiento y reducir costos, pero solo si se entiende qué se está guardando y cuándo deja de ser válido.